Można wymyślać temu malowaniu różne interpretacje, ale ma ono swój konkretny kontekst historyczny, i bez jego znajomości wyjdą z tego jakieś głupoty. Więc od opowiedzenia tej historii zacznę tę notkę, a wszystko będzie bardzo na temat podany w tytule.
Ten IS-2 od roku 1945 stał w Pradze jako pomnik armii radzieckiej. Namalowany na nim był numer 23. Miał to niby być pierwszy radziecki czołg, który dotarł do Pragi, ale to był tylko mit. Do Pragi dotarły czołgi T-34, pierwszy z nich miał numer I-24. Akurat ten czołg został zniszczony w trakcie walk, więc rosjanie przysłali na pomnik coś lepszego. Czołg stanął na wysokim postumencie (5 metrów), a lufę miał skierowaną na zachód.
Następnym wydarzeniem związanym z tym czołgiem było wyjęcie mu silnika i skrzyni biegów. Rosjanie zrobili to w roku 1956, po wydarzeniach na Węgrzech. Z innych czołgów-pomników też pousuwano silniki, żeby nie mogły być wykorzystane przeciw władzy ludowej. Myślę, że te obawy nie były całkiem bezpodstawne - przypominam sobie filmik z początku wojny w Ukrainie, gdzie ukraińscy cywile uruchamiali właśnie takiego, pomnikowego IS-2, i udało im się go odpalić i pojechać. Nie wiem, czy czołg ten został jakoś użyty bojowo, ale wynika z tego że na terenie ZSRR silników z pomników nie usunięto.
W roku 1968 numer 23 namalowany na czołgu zyskał ironiczno-symboliczny kontekst, bo - jak zauważono 1945 + 23 = 1968. Zadra ówczesnych wydarzeń tkwi w Czechach do dziś - na przykład w drugim odcinku serialu Kosmo jest scena, kiedy wyniesienie czeskiego statku kosmicznego na księżyc proponują rosjanie, propozycja jest z gatunku nie do odrzucenia, a stawia ją generał który "brał udział w wyzwalaniu Czechosłowacji". Gdy zdziwionemu czeskiemu ministrowi wydaje się, że generał jest na to trochę zbyt młody dowiaduje się, że chodziło o "to drugie wyzwolenie".
Przez następne lata czołg stał nie niepokojony, aż 28 kwietnia 1991 na scenę wkroczył 23-letni student praskiej ASP David Černý. Černý był już trochę znany ze swojego Trabanta z nogami, odnoszącego się do exodusu enerdowców przez ambasadę RFN w Pradze w 1989. Tym razem z kolegami pomalowali ten czołg na różowo. Gdyby ktoś się zastanawiał, czy mieli przy wyborze koloru na myśli różowe kucyki albo jednorożce, to podam brakujący szczegół: na wieży czołgu Černý umieścił wielki, różowy, wyprostowany środkowy palec. Teraz chyba jest już jasne, o jaki odcień różowego chodziło. (Uwaga na marginesie: Lady Pank miało różowego Shermana już w 1985, w nagranym w USA klipie do piosenki "Minus zero", ale kontekst był jednak zupełnie inny).
Związek radziecki wystosował zaraz notę protestacyjną (przecież było to na kilka dni przed dziewiątym maja!), Černý został zaraz zamknięty za zakłócanie porządku, a czołg szybko (w ciągu trzech dni) pomalowano znowu na zielono. Cała akcja wywołała ogólnonarodową dyskusję, i wkrótce grupa parlamentarzystów z partii Forum Obywatelskie (Občanské fórum, z tej partii był Vaclav Havel) korzystając z immunitetów poselskich pomalowała czołg znowu na różowo. Środkowy palec jednak tymczasem zaginął, stąd nie ma go na zdecydowanej większości starych zdjęć pomalowanego czołgu. Wkrótce czołg zdjęto z postumentu i przewieziono do Muzeum Lotnictwa w Kbely, a potem do muzeum w Lešanach. Natomiast David Černý stał się dzięki swojej akcji naprawdę znany.
Dziś, gdy widzicie w Czechach jakąś rzeźbę albo instalację współczesną, zwłaszcza kontrowersyjną, to na 95% jej autorem jest David Černý. Nie będę tu robił monografii, można poguglać i dużo się znajdzie, ale o dwóch rzeczach opowiem:
Pierwsza to rzeźba znajdująca się w Pradze, w pasażu w Pałacu Lucerna, blisko Václavského náměstí. Rzeźba ma tytuł "Kůň" ("Koń"), powstała w roku 1999 i jest wyraźną parodią pobliskiego pomnika świętego Wacława.
David Černý "Koń"
Swięty Wacław
Na pierwszy rzut oka to jest po prostu śmieszne, ale jak się zastanowić i porównać parodię z oryginałem (stoi o rzut beretem), to można się dogrzebać wielu różnych warstw interpretacyjnych i dojść do interesujących przemyśleń. Oglądałem kiedyś w telewizji (niemieckiej) program, w których reporterka chodziła z Davidem Černým po Pradze i rozmawiała o jego dziełach. Z tego autor nie był za bardzo zadowolony (bo "koń nie wyszedł całkiem poprawny anatomicznie"), ale według mnie to akurat nieistotne, dzieło jest dobre i daje do myślenia.
Druga rzecz to wystawa "Český betlém" ("Czeska szopka"), którą widziałem w Muzeum Skody w Mlada Boleslav (ale to było w 2018, nie mam pojęcia gdzie jest teraz). Wystawa składa się z kilku dioram w formacie małego do średniego stołu, na oko wykonanych z brązu. Dyskretnie postukałem paznokciem w podstawę jednej z nich i rzeczywiście był to odlew z brązu. Tyle że te dioramy zawierają tyle szczegółowych obiektów, że z wykonanie ich z brązu mogłoby być problematyczne. Ale ja się nie znam i nie próbowałem dotykać tych delikatnych kawałków. Każda z dioram przedstawia jakieś wydarzenie z historii Czech. Zacznijmy od takiej sceny:
David Černý "Czeska szopka" - Hanzelka i Zikmund w Afryce
Oczywiście trzeba być Czechem żeby kojarzyć wszystkie te wydarzenia i ich kontekst, to jest przecież czeska szopka, ja musiałem poczytać. Tu chodzi o dwóch dziennikarzy (Jiří Hanzelka i Miroslav Zikmund), którzy w latach 1947-1950 pojechali Tatrą 87 do Afryki i Ameryki Łacińskiej, i tam realizowali filmy i reportaże radiowe, powszechnie słuchane w kraju. Ich Tatra znajduje się teraz w Muzeum Techniki w Pradze.
Tatra 87 Hanzelki i Zikmunda
Tutaj mamy wizytę Rolling Stonesów u prezydenta Havla na Hradčanach (1995). Jak widać, oprócz elementów realistycznych w dioramach znajdują się też elementy fantastyczne, a bywają nawet SF.
David Černý "Czeska szopka" - Rolling Stonesi u Havla na Hradčanach
Dużo dzieje się też z dala od centrum, a od tyłu dioramy, a nawet pod spodem.
David Černý "Czeska szopka"
A tu mamy enerdowców uciekających do ambasady RFN w Pradze i koczujących na jej terenie, mamy też czworonożnego Trabanta.
David Černý "Czeska szopka" - Enerdowcy uciekają do ambasady RFN w Pradze
David Černý "Czeska szopka" - Enerdowcy w ambasadzie RFN w Pradze
Jest tego więcej. Jeżeli będziecie mieli okazję zobaczyć Czeską Szopkę, to bardzo polecam. Černý dobry jest.
Dziś będzie znowu mocno zaległa notka i to o wojnie.
Lepiej lub gorzej, ale pewnie wszyscy pamiętają katastrofę tamy elektrowni wodnej w Nowej Kachowce, która zdarzyła się szóstego czerwca 2023. Wtedy Ukraina oskarżyła o wysadzenie tamy Rosję, Rosja Ukrainę, a niemal wszyscy eksperci mieli swoje zdanie kto i jak tamę wysadził. Ale przecież na 100% wysadził, inaczej być nie mogło.
Zanim pójdę dalej, opiszę konstrukcję tej tamy, bo to istotne. Tama została ukończona w roku 1956 i była projektowana tak, że miała wytrzymać atak jądrowy. Była naprawdę duża - 30 metrów wysokości i 3273 metrów długości. Tama składała się z paru segmentów (będą opisywał patrząc od dolnej strony, bo od tej jest większość zdjęć, ale podejrzewam że fachowo i w dokumentacji technicznej patrzy się od góry rzeki). I tak:
Po lewej znajduje się 28 bram do spuszczania wody, każda ma regulowane wrota. Do otwierania i zamykania wrót służą dwie ruchome, jeżdżące po torach suwnice na szczycie zapory. Numery bram są liczone od strony elektrowni.
Na prawo od tego segmentu jest elektrownia wodna z sześcioma turbinami.
Dalej na prawo jest trochę innych instalacji, na przykład śluza.
Droga dla samochodów nie idzie koroną zapory, tylko na podporach od strony dolnej (dołu rzeki, nie dołu zapory). Od strony górnej jest linia kolejowa.
UWAGA: Jeżeli na zdjęciu poniżej wychodzi ci mniej niż 28 bram, to masz rację. To panorama złożona z iluś zdjęć, i aparat, program albo człowiek sklejający zdjęcia wyraźnie się pomylił. Niedokładne łączenie widoczne jest między 10 a 11 bramą od lewej, 6 bram "zaginęło w akcji". (To akurat moja analiza, liczyłem te bramy na różnych zdjęciach i się nie zgadzało, więc przed publikacją notki musiałem znaleźć dlaczego).
I znalazł się tylko jeden ekspert (a raczej grupa ekspertów), który rzeczywiście przeanalizował dostępne zdjęcia i materiały wideo z katastrofy oraz materiały historyczne i wyciągnął z nich dobrze umotywowane wnioski. Wszyscy inni rzucili okiem i od razu wiedzieli jak było. Wnioski grupy o której piszę zostały później potwierdzone innymi metodami i w tej chwili jest dokładnie wiadomo, co się tam stało, ale jak zwykle prawda ginie pod stertą głupot. Na przykład polska Wiki w ogóle pomija sobie temat przyczyn katastrofy, niemiecka skłania się ku wersji wysadzenia przez rosjan, a angielska rozważa również inne warianty, ale bez wskazywania najbardziej prawdopodobnego.
Ekspertem robiącym porządną analizę był Rusłan Lewijew. To ciekawa postać, więc o nim opowiem. On jest Rosjaninem, urodził się w 1986. Studiował prawo karne na uniwersytecie, a amatorsko interesował się informatyką. Jeszcze przed końcem studiów stracił ostatnie złudzenia co do praworządności w Rosji, rzucił studia i zaczął pracować jako programista.
Wkrótce zaangażował się w działalność opozycyjną, a potem (2012) dostał zlecenie na zrobienie strony w sieci do monitorowania wyborów dla Fundacji Walki z KorupcjąNawalnego. Ponieważ dobrze zrobił tę stronę, wkrótce pracował bezpośrednio w centrali tej fundacji. W 2014 podczas Euromajdanu i aneksji Krymu zaczął zajmować się analityką, i to szło mu bardzo dobrze. Wkrótce połączył swoje siły z innymi analitykami OSINTowymi (czyli uprawiającymi "biały wywiad") zakładając Conflict Intelligence Team (w skrócie CIT). Do zespołu należy jeszcze kilka osób (ale niedużo, tak z pięć). Jedynym znanym z nazwiska jest sam Lewijew, on jest "twarzą" tego zespołu i tylko on pojawia się w mediach i prezentuje wyniki prac. Zespół zajął się monitorowaniem działalności wojsk rosyjskich w różnych konfliktach. Lewijew opowiada różne anegdoty z tego okresu, na przykład gdy potrzebowali niedostępnych w otwartym dostępie wymiarów jednej z rosyjskich rakiet, znaleźli w którym muzeum wojskowym jest wystawiona, Lewijew ze swoją dziewczyną pojechali tam, dziewczyna odwróciła uwagę obsługi, a w tym czasie Rusłan zmierzył rakietę po prostu miarką.
Po ataku rosji a Ukrainę Rusłan wyjechał z kraju na emigrację, aby móc kontynuować swoją działalność. Wkrótce potem został zaocznie aresztowany (serio - in absentia, nie wiedziałem, że taki tryb aresztowania istnieje), oskarżony o różne przestępstwa typu deprecjacja armii, rozpowszechnianie fejków i bycie zagranicznym agentem, i zaocznie skazany na (o ile dobrze pamiętam) 11 lat kolonii karnej. Po pewnym czasie zaczął prezentować wyniki analiz swojego zespołu na youtubie, trzy razy w tygodniu, w rozmowach z Majklem Nakim (nie wiem, jak jego imię i nazwisko zapisać po polsku, za chwilę wyjaśnię dlaczego) na jego kanale @MackNack.
Majkl Naki to też bardzo ciekawy gość, teraz trochę o nim. On urodził się w Rosji (1993) jako syn obywatela USA i Rosjanki. Ma dwa obywatelstwa - rosyjskie i amerykańskie - ale w USA był tylko jako małe dziecko, a po angielsku mówi słabo. Co do nazwiska: on po angielsku nazywa się Michael Sidney Nacke, a po rosyjsku Майкл Наки czyli fonetycznie właśnie Majkl Naki. W Rosji studiował ekonomię, skończył na bakalaureacie, pracę pisał na temat korupcji. Potem pracował w radiu, zaczął też prowadzić swój kanał na youtubie (od 2012). I cały czas był raczej opozycyjny.
Trochę po wybuchu wojny z Ukrainą Naki wyjechał z rosji i zaczął zajmować się przede wszystkim swoim kanałem youtubowym. Omawia sytuację na froncie, wydarzenia w rosji i wszystko, co ma związek z wojną. I - tak jak i Lewijew i wielu innych opozycyjnych emigrantów - został zaocznie skazany na 11 lat kolonii karnej. Naki dawna już wypuszcza dwie audycje po 30-60 minut dziennie, przedpołudniowa jest o froncie i wydarzeniach, popołudniowa o tym, co piszą rosyjskie media, przede wszystkim Z-Wojenkory i Z-blogerzy. Idea analizy co mówią propagandyści jest taka, że wiadomo że oni kłamią jak najęci (a nawet są do tego najęci), ale jeżeli zaczynają mówić o jakimś problemie strony rosyjskiej, to znaczy że ten problem jest już bardzo poważny. Kiedyś w poniedziałki środy i piątki przed południem rozmawiał o sytuacji na froncie z Lewijewem, potem grupa CIT stwierdziła, że po pierwsze nie utrzyma tego tempa, a po drugie że lepiej będą pracować na siebie, więc założyła swój kanał @CITeam_org. Publikują tam raz na tydzień, w środy, audycje po 40-60 minut. Naki nadal w soboty po południu rozmawia o sytuacji ekonomicznej rosji z Władymirem Miłowem, ekonomistą, byłym wiceministrem energetyki rosji (w początku dwutysięcznych). To też ciekawy gość, ale może dość dygresji, dam tylko link do jego kanału: @Vladimir_Milov. Naki to jest rozsądny, inteligentny i dowcipny gość z zasadami i trzeźwym oglądem rzeczywistości, którego miło posłuchać (rozsądnego zawsze miło posłuchać). Utrzymuje się on z Patreona i jest jedynym znanym mi rosyjskim opozycjonistą, który prowadzi zbiórki na broń i wyposażenie dla armii Ukrainy. Jego kanał youtubowy ma ponad dwa miliony subskrybentów.
Wróćmy do Lewijewa. Jego CIT zdobyło tymczasem taką renomę, że Rusłan (za Bidena) jeździł do USA i uczył amerykańskich analityków wojskowych jak się robi porządne analizy. Oni są naprawdę dobrzy w te klocki, pamiętam na przykład sprawę, gdy na główną ulicę jakiegoś miasteczka w Ukrainie spadła rakieta i zabiła trochę ludzi. Zespół CIT przeanalizował dostępne publicznie zapisy kamer monitoringu klatka po klatce, i na jednej z klatek zauważyli odbicie spadającej rakiety w szybie zaparkowanego samochodu. Zlokalizowali miejsca w którym stał samochód i w którym była zainstalowana kamera na google maps, przeliczyli kąty odbić i znając punkt gdzie rakieta spadła ustalili kierunek z którego przyleciała. I wyszło, że niestety była wystrzelona z Ukrainy. Potem jeszcze na podstawie jej przybliżonych wymiarów ustalonych według odbicia i charakterystyk jej elementów porażających udało im się nawet ustalić konkretny typ rakiety. Lewijew przedstawił całe rozumowanie i wszystkie materiały z których korzystali, i nie było się do czego przyczepić.
Dobrzy są, warto ich posłuchać. A teraz powróćmy do ich analizy katastrofy tamy.
Większość analityków twierdziło, że tamę wysadzili rosjanie podkładając ładunek wybuchowy w części z turbinami (bo tam prościej), jako "dowód" służyło zdjęcie satelitarne ciężarówki z domniemanym ładunkiem materiałów wybuchowych, stojącej na tamie. Tymczasem Lewijew przyjrzał się opublikowanemu filmikowi nagranemu przez rosyjskich żołnierzy. Przyjrzyjcie się kadrowi z tego filmiku poniżej (link do całego odcinka rozmowy, screenshot jest z 21:11):
Tama w Nowej Kachowce chwilę po awarii (Źródło: Żołnierze rosyjscy, via youtube kanał @macknack)
Na kadrze widać że tama jest już przerwana, ale budynek elektrowni - w którym miała by być ta eksplozja niszcząca tamę - jest cały. Wniosek jest prosty - nie było żadnej eksplozji w elektrowni. Każdy ekspert, który twierdzi że była nie odrobił zadania domowego albo nie jest żadnym ekspertem. Dalej zespół poszukał wcześniejszych zdjęć tamy oraz historycznych danych o stanie wody, i porozmawiał ze specjalistą od budowli hydrotechnicznych znającym tę konkretną zaporę, i wtedy zrobiło się ciekawie.
Ekspert kategorycznie stwierdził, że bramy zawsze należy otwierać symetrycznie i zaczynając od środka, i dlatego właśnie suwnice do bram są dwie. Natomiast rosjanie przy wycofywaniu się z Chersonia wysadzili trzy przęsła drogi dla samochodów, toru kolejowego i toru dla suwnic od prawej strony rzeki (bramy 26 i 28), pozamykali wrota na środku, a maksymalnie otworzyli dwa blisko skraju po prawej stronie na zdjęciu (bramy 3 i 4). Stan wody był wtedy bardzo niski.
Tama w Nowej Kachowce na kilka dni przed awarią (Źródło: MAXAR via youtube kanał @macknack)
Potem minęło osiem miesięcy, podczas których stan wrót ani razu nie został zmieniony. Tymczasem wody bardzo przybyło, aż do rekordowego stanu. Na zdjęciu satelitarnym widać, że woda nawet zaczęła się przelewać ponad zamkniętymi wrotami, czyli była powyżej jakichkolwiek dopuszczalnych stanów. Przy normalnej obsłudze do takiej sytuacji nie powinno w ogóle dojść, bo normalnie to wodę się upuszcza do właściwego poziomu. Przez otwarte, bliskie skraju wrota woda zasuwała na maksa, a to jest groźne dla stabilności zapory. Ekspert stwierdził że to cud, że wytrzymała coś takiego aż osiem miesięcy. Potem, na dzień przed awarią, spadło jedno z przęseł drogi przez tamę. Nie, nie było żadnego ostrzału, i tak nie miałby żadnego sensu i od dawna go już nie było.
Kiedy relacjonowałem to wszystko ojcu, który przez całe swoje życie zawodowe zajmował się liczeniem konstrukcji budowlanych, nie doszedłem nawet do połowy, a on już dokładnie wiedział co się stało. Czy też już załapaliście? Tama po prostu nie wytrzymała niewłaściwej eksploatacji. Nikt nic nie wysadzał, ale wina jest oczywiście po stronie rosjan - tama była pod ich kontrolą, i ich psim obowiązkiem była eksploatacja jej zgodnie z instrukcją. I nie mogą się tłumaczyć że nie mieli dokumentacji, bo ona jest w bibliotece w rosji, a symetryczne otwieranie obowiązuje dla każdej takiej konstrukcji.
Tama oczywiście porusza się na skutek zmian temperatury, poziomu wody itp. Tak normalnie, to powinna wrócić do pierwotnego położenia po ustąpieniu czynnika odkształcającego.
Oprócz tego części tamy powolutku ustępują pod naporem wody, na przykład ze względu na kompresję gleby po fundamentem, ślizganie się po gruncie itp.
Tempo tego ustępowania we wcześniejszych latach było rzędu 2 mm/rok.
Od 2021 (czyli jeszcze przed wojną) tempo ustępowania wzrosło. Chociaż jak patrzę na wykresy, to może to kwestia aproksymowania zaszumionego przebiegu prostymi, w którym momencie tempo faktycznie wzrosło można dyskutować.
Tama została zajęta przez rosjan 24.02.2022, od tego momentu zaczęła się nieprawidłowa eksploatacja tamy.
Zaproksymowane prostą tempo odkształcania tamy po zajęciu wyszło im rzędu 8 mm/rok, a miejscami nawet 20. Czyli minimum kilkukrotnie większe niż wcześniej.
Pomiary satelitarne nie mogą oczywiście wykluczyć wybuchu, ale wskazują że scenariusz bezwybuchowy jest 100% możliwy, a nawet prawdopodobny.
Teraz wnioski:
Ruska propaganda na Zachód wszelkimi kanałami wciska, że prawdy już nie ma, że wszystkie punkty widzenia są równoważne, i podobny chłam. W rzeczywistości ustalenie prawdy jest w dzisiejszych czasach łatwiejsze niż kiedykolwiek. Kiedyś nie dało by się dotrzeć do nawet drobnej części tych danych, jakie dziś są w sieci w publicznym dostępie. Problem jest tylko taki, że trzeba dobrze używać mózgu, ale ten problem istniał zawsze.
Nadal podstawowym narzędziem analizy jest logika, można wiele wywnioskować nawet bez dużej wiedzy branżowej, ale zapytać fachowca zawsze warto.
Pytanie fachowca też nie jest trywialne, dziennikarze śledczy z renomowanych tytułów też pytali fachowców i otrzymywali odpowiedzi na zadane pytania. Odpowiedzi były poprawne, ale nie pasujące do konkretnego przypadku, więc wnioski ich nie były poprawne.
Ale co z tego, że ktoś doszedł do prawdy, skoro i tak mało kto tę prawdę usłyszy/przeczyta/przekaże dalej?
W sumie tak, czy owak 22. Spodziewałem się tego już od dawna, ale nie że tak szybko.
EDIT 05.10.2025: Jeszcze jeden przyczynek do eksperckości. Wysłuchałem właśnie eksperta Wolskiego, który perorował że rosyjskie problemy z benzyną nie mają wpływu na front, bo wszystko wojskowe jeździ na ropie. Powiem tak: Wolski na pewno zna się na czołgach i ruchach wojsk, ale nie zna rosyjskiego, stąd jego opinie na temat sytuacji politycznej, społecznej i ekonomicznej w rosji są bezwartościowe. Eksperci rosyjskojęzyczni od dawna zwracają uwagę, że ciężarówki i sprzęt ciężki na ropę w okolicach frontu od dawna praktycznie nie występują. Całe zaopatrzenie pierwszej linii idzie Buchankami, przerabianymi samochodami cywilnymi i motocyklami, wszystko benzyna, a żołnierze kupują paliwo na stacjach benzynowych, gdzie tego paliwa brakuje. A, jeszcze niezbędne chociażby do ładowania akumulatorów dronów i aparatury do ich sterowania generatory spalinowe też potrzebują benzyny. Jeżeli brak benzyny ma nie mieć żadnego wpływu na front, to co taki wpływ ma?
To nie jest wcale pierwszy raz kiedy Wolski gada głupoty na podobne tematy, a wynika to z tego, że on musi korzystać z wiadomości z drugiej (albo i trzeciej) ręki. I nie on jeden tak musi.
Opisuję na moim blogu różne rzeczy, które zrobiły na mnie wrażenie, i mam jedną rzecz która wrażenie zrobiła już w 2018 i od tego czasu trzyma. Wrażenie pochodzi z Pragi.
Zacznijmy od nawiązana do fantastyki: Dawno, dawno temu w Nowej Fantastyce było opowiadanie Jamesa Patricka Kelly'ego pod tytułem "Myśleć jak dinozaury" ("Think Like a Dinosaur"). Szło tam o technologię podróży międzygalaktycznych przez zdalne wykonywanie kopii podróżującego. Technologia pochodziła od Obcych wyglądających jak dinozaury, stąd tytuł. Problemem (chociaż jak dla kogo, bo dla tych tytułowych dinozaurów nie był to żaden problem) tej technologii było to, że oryginał transmisji musiał być zniszczony po otrzymaniu potwierdzenia poprawności transmisji, bo wszechświat musiał się bilansować. Więc jeżeli potwierdzenie się opóźniło, to oryginał musiał po prostu wejść powtórnie do skanera, żeby dać zniszczyć siebie, a nie cały wszechświat. Do tego trzeba myśleć nie jak człowiek, a jak te dinozaury. I jeżeli człowiek w takiej sytuacji odmawiał samozniszczenia, trzeba było za wszelką cenę jak najszybciej przywrócić równowagę ubijając go. Czyli tak w sumie to chodziło o wariant dylematu zwrotnicy - czy ubić oryginał bliskiego człowieka żeby uratować świat?
Historia zamachu na Heydricha jest długa i mocno kontrowersyjna. Nie będę jej tu opisywał we wszystkich szczegółach, bo wyszłaby spora i bardzo smutna książka o złym przygotowaniu, błędnych ocenach, nieszczęśliwych przypadkach, tragicznych skutkach i zwłaszcza jednym, wyjątkowo okropnym człowieku. Napiszę tylko o dwóch powiązanych z tym zamachem zdarzeniach, oraz wprowadzę tylko tyle tła, ile trzeba dla zrozumienia tego dinozaurowego zdarzenia.
Pierwsze wydarzenie: Akcja z zamachem niezupełnie się udała - Sten z którego strzelali zamachowcy zaciął się, a rzucony ładunek wybuchowy eksplodował poza samochodem Heydricha i on został tylko ranny (chociaż dość poważnie). Heydrich chciał, żeby operował go lekarz z Niemiec, ale nie było na to czasu. Operacja przeprowadzona przez czeskiego lekarza powiodła się i Heydrich zaczął zdrowieć, ale potem coś nieustalonego (chyba sepsa, ale są i inne teorie) się przyplątało i zmarł. W sumie to niewykluczone, że nie zabili go zamachowcy, tylko jakiś bezimienny pracownik szpitala zawlekając mu, być może celowo, zakażenie szpitalne. Przez zamachowców zginęła masa ludzi, przez tego pracownika szpitala tylko ten jeden, o którego chodziło.
Mercedes Benz W142 Heydricha po zamachu.
Teraz trochę tła. Zamach na Heydricha jest tu istotny.
W końcu roku 1941 emigracyjny rząd czechosłowacki w Londynie wspólnie z wywiadem brytyjskim zorganizował zrzut kilku grup spadochroniarzy, którzy mieli prowadzić akcje dywersyjne na terenie Protektoratu Czech i Moraw. Słowa kluczowe do szukania to Anthropoid (ta grupa miała dokonać zamachu na Heydricha), Silver A, Silver B, Out Distance, Zinc i Bioscop. Pierwsze trzy grupy zostały zrzucone w końcu grudnia 1941, czwarta i piąta w marcu, a szósta w kwietniu 1942.
W tym czasie poziom represji okupantów w stosunku do czeskiej ludności cywilnej był relatywnie niski. (read my lips: relatywnie). Większość problemów wszystkich zrzuconych spadochroniarzy wynikała ze słabego przygotowania akcji i nieznajomości realiów życia pod okupacją przez organizatorów (nie będę wnikał w szczegóły, poczytajcie).
Po sukcesie zamachu w końcu maja 1942 wszystko gwałtownie się zmieniło - zaczęły się ostre represje. Widząc to, dwóch ze spadochroniarzy poszło na współpracę z Niemcami, byli to Karel Čurda (z grupy Out Distance) i Viliam Gerik (z grupy Zinc). Na podstawie ich zeznań aresztowano i stracono mnóstwo osób, zarówno bezpośrednich ich kontaktów, jak i kontaktów kontaktów i dalej. Obaj zostali solidnie nagrodzeni, a potem pracowali jako prowokatorzy (znaczy jest to dobrze udokumentowane dla Čurdy, ale nie znajduję nic konkretnego o Geriku, tylko że potem próbował z tej współpracy wyjść). Oni pukali do losowo wybranego mieszkania i podawali się za spadochroniarzy, kto takiemu dał schronienie ten był aresztowany. Nie będę tu wnikał w ich motywacje, wiele na ten temat można znaleźć w sieci.
Zmierzam do tego, że to przy wysokim poziomie represji każdy kontakt zapisany w notesie bojownika w przypadku wpadki mógł stać się wyrokiem śmierci dla zapisanego i jego kontaktów.
Teraz dochodzimy do myślenia jak dinozaury, mam na myśli los członka grupy Silver A nazwiskiem Jiří Potůček. Ponieważ Potůček nie miał już gdzie się ukryć (wszystkie kontakty bały się go przyjąć albo nie chciał ich narażać), spał gdzieś w krzakach, i tam odkrył go czeski policjant Karel Půlpán. Odkrył, i stanął przed realnym (a nie teoretycznie wykombinowanym) dylematem zwrotnicy. Według reguł, powinien go aresztować, Potůček powinien zostać przesłuchany, wysypać swoje kontakty, a sama zawartość jego notesu byłaby wyrokiem śmierci dla iluś osób, a potem dla ich kontaktów, kontaktów kontaktów, itd.
I tu Půlpán rozwiązał dylemat zwrotnicy myśląc jak dinozaury - zastrzelił budzącego się Potůčka, a potem zniszczył jego notes, czyli zminimalizował straty ludzkie. Zimna racjonalność jego decyzji po prostu mnie powala. Tak to zostawię, bez dalszych komentarzy.
Epilog: Po wojnie Půlpán został skazany na 7 lat więzienia (zniszczenie notesu było okolicznością łagodzącą).
Po dwóch poprzednich odcinkach czytelnikowi może się wydawać, że nie doceniam aktualnego stanu prac nad generatywnym AI, a nawet go wyśmiewam. To nie jest tak. W porównaniu z tym, jak wyglądało automatyczne tłumaczenie dziesięć lat temu, to aktualne to rewelacja. Do generacji tekstów i obrazków można mieć wiele zastrzeżeń, ale to już jest naprawdę coś. Moje uwagi wynikają przede wszystkim z tego, że to wcale nie jest pierwszy hype na AI, a od zawsze miała ona zastąpić człowieka. Prawie tak, jak ta automatyczna generacja kodu z poprzedniej notki.
A było to tak:
"Perceptron", czyli sieć neuronową z użyciem "sztucznych neuronów" wymyślono teoretycznie w roku 1943, pierwszy komputer oparty na perceptronach (Mark I Perceptron) zbudowano w roku 1957. Hype na ten "sztuczny mózg" był taki, że przez dłuższy czas wszelkie komputery nazywano "mózgami elektronowymi", i miały one zastąpić człowieka we wszystkim.
Mark I Perceptron. Źródło: https://americanhistory.si.edu
IBM próbował stworzyć "Rozwiązywacz problemów wszelakich" ("General Problem Solver") już w roku 1959. (oczywiście nie wyszło).
W sześćdziesiątych i siedemdziesiątych faktyczne osiągnięcia w AI były dość umiarkowane, głównie ze względu na brak mocy obliczeniowej ówczesnych komputerów. Ale hype, chociaż mniejszy, istniał nadal - na przykład w sporej części SF istotną rolę grał duży, inteligentny i samoświadomy komputer komunikujący się z użytkownikami głosowo (na przykład w "Luna to surowa pani" Heinleina).
W siedemdziesiątych zdarzył się jednak Cybersyn - projekt który nie został zakończony i raczej nawet gdyby go zakończyć nie dałby spodziewanych rezultatów, ale na wyobraźnię podziałał.
Rozwój AI istotnie przyspieszył w osiemdziesiątych. Rozpoczęto na przykład próby z autonomicznymi pojazdami, zarówno wojskowymi, jak i cywilnymi. SF pokazywała autonomiczne roboty (np. "Terminator"). Według hype AI miała na początek zastąpić zawody żołnierza i kierowcy.
Nawet w takim NRD uważano AI za ratunek dla kraju i prowadzono intensywne (choć w tak naprawdę mało obiecujące) prace nad tym tematem.
W dziewięćdziesiątych pojawiły się dostępne nawet dla amatora programy do analizy technicznej kursów giełdowych, oparte na sieciach neuronowych. Hype mówił, że wyeliminują one zawód tradera.
W dwutysięcznych hype trochę opadł - prace nad AI posuwały się intensywnie, ale wyraźnie było widać że wyniki sa dość odległe od wygórowanych oczekiwań. Automatyczne tłumaczenie było marne, autonomiczne pojazdy nie nadawały się za bardzo do wypuszczenia ich samodzielnie na drogę, praktycznie działały jedynie zabawki w rodzaju "Furby", albo autonomiczne odkurzacze. A powiedzmy sobie otwarcie, że autonomiczny odkurzacz to poziom trochę lepszego "cybernetycznego żółwia" z sześćdziesiątych.
Najnowszy hype na generatywne AI nie jest więc niczym nowym.
Generalnie to prawie każda nowa technologia w trakcie jej rozwoju generuje cykle hype-hate. Tak typowo to ani nie jest z nią tak dobrze jak odczuwa się to w fazie hype, ani tak źle jak odczuwa się w fazie hate. Nie inaczej jest z AI.
Współczesne AI świetnie nadaje się do wykrywania wzorców w danych wejściowych, tu pojawia się sporo istotnych zastosowań i dokonanych dzięki niej odkryć. AI generatywna jest jednak w fazie over-over-hype. Ona coś już potrafi, to robi wrażenie, ale realistycznie patrząc to do zastępowania człowieka jest jej bardzo daleko. I to nie jest tak, że wystarczy trochę skorygować implementację, dać szybszy komputer albo więcej pamięci i już - nie, ograniczenie tkwi w samej jej koncepcji. żeby zrobiło się znacząco lepiej potrzeba nowej koncepcji. I to nie będzie rok czy dwa.
Moja prognoza (żadna tam szklana kula czy głęboka futurologia - po prostu będzie tak, jak zawsze):
W najbliższych latach będzie się próbować wtykać generatywną AI wszędzie, gdzie tylko się da. Powstanie trochę w miarę użytecznych narzędzi, ale
generalnie efekty tego będą takie sobie, znacznie poniżej oczekiwań.
Hype powoli przejdzie w hate.
Tymczasem będzie się pracować nad nowymi koncepcjami
Cykl się powtórzy. Następny hype będzie za 10-20 lat.
Czyli na Zachodzie bez zmian. Generalnie można spać spokojnie, AI miejsca pracy wam raczej nie zabierze. Jakieśtam, ewolucyjne zmiany w pracy w różnych zawodach na pewno będą, ale nie takie, żeby zaraz połowę pracowników wyrzucać (A jeżeli jakiś zbyt łatwowierny manager mimo wszystko połowę wyrzuci, to wkrótce pożałuje).
A już zwłaszcza nie za wiele zmieni się w zawodzie programisty. CEO Nvidii Jensen Huanguważa, że przyszłe pokolenia w ogóle nie będą musiały uczyć się języków programowania, ale według mnie to zależy od definicji "języka programowania". Pan Huang ma chyba definicję bardzo zawężoną do języków imperatywnych - i tu nawet mógłbym się zgodzić. Programowanie imperatywne to prowadzenie komputera za rączkę, i na dłuższą (ale naprawdę dłuższą, chyba nawet nie za mojego życia) metę powinno to się zmienić. Ale na językach imperatywnych świat się nie kończy, mamy jeszcze bardzo szeroki wybór języków deklaratywnych. Taki na przykład Prolog powstał już w roku 1972, i od początku był uważany za "język sztucznej inteligencji".
Dalej pan Huang stwierdził: "It is our job to create computing technology such that nobody has to program and the programming language is human. Everybody in the world is now a programmer”. Ale jakoś przecież musimy komputerowi (nawet sztucznie inteligentnemu komputerowi) powiedzieć, czego dokładnie od niego chcemy. Zresztą żywym programistom/architektom też musimy to jakoś powiedzieć, i użycie przy tym języka naturalnego od zawsze jest jednym z najpoważniejszych źródeł problemów. Do tego stopnia, że już dziś przy tworzeniu requirementów używamy co prawda języka naturalnego, ale częściowo sformalizowanego (na przykład jest dokładnie zdefiniowane, w jakiej sytuacji piszemy "shall", w jakim "should", a w jakiej "may". Takich reguł jest więcej). Przy formułowaniu requirementów używamy formalnych notacji matematycznych (np. "6V < Ubatt < 18V"), wzorów matematycznych i diagramów w sformalizowanych notacjach (np. UML czy SysML). Wiele typów tych diagramów potencjalnie daje się automatycznie przekształcić w wykonywalny kod przy użyciu różnych generatorów kodu (BTDT), co według mnie spełnia definicję "języka programowania". Użycie języka naturalnego do programowania uważam za mrzonkę, to nigdy nie działało dobrze i nie będzie dobrze działać.
Ale najśmieszniejsze jest to jego "Everybody in the world is now a programmer". Całkiem podobne hasła towarzyszyły rozposzechnieniu internetu i prostych Authoring Tools. Everybody in the world miał być now kreatywnym muzykiem, grafikiem, pisarzem, poetą, filmowcem, popularyzatorem nauki czy kim tam jeszcze. Dostaliśmy garść wartościowych artystów, i miliony tiktokerów, influencerów i szurów. Nie jestem pewien, czy było warto. Większość ludzi wcale nie chce być artystą albo programistą, a większość tych którzy chcieli by być (zwłaszcza bez włożenia w to wysiłku), wcale się do tego nie nadaje.
TL;DR? Będzie jak zawsze. Zmiany ewolucyjne, nie rewolucyjne.
Zawodem szczególnie podatnym na zastąpienie przez AI miałby być zawód programisty. Tak przynajmniej można ostatnio usłyszeć i przeczytać w różnych mediach. Zastanówmy się, czy tak naprawdę jest. Bo przecież AI może wygenerować śliczny kod programu na podstawie opisu, co ten program ma robić. Może, prawda? Prawda?
Zacznijmy od tego, że mówimy o kodowaniu, czyli pisaniu tekstu, który po przekształceniu jest wykonywany przez komputer - aktualna AI nie potrafi przecież nic innego niż generowanie tekstów. Tyle że nawet gdyby AI naprawdę wygenerowała nam śliczny i bezbłędny kod, to i tak nie eliminuje to zawodu programisty, a co najwyżej kodera. Programowanie to cały proces, kodowanie to tylko jeden, najmniejszy jego etap. Programowanie z kodowaniem utożsamiają tylko ludzie nie mający o tym pojęcia, co bardziej amatorscy programiści-amatorzy i może jeszcze jakieś dziadowskie firmy programistyczne.
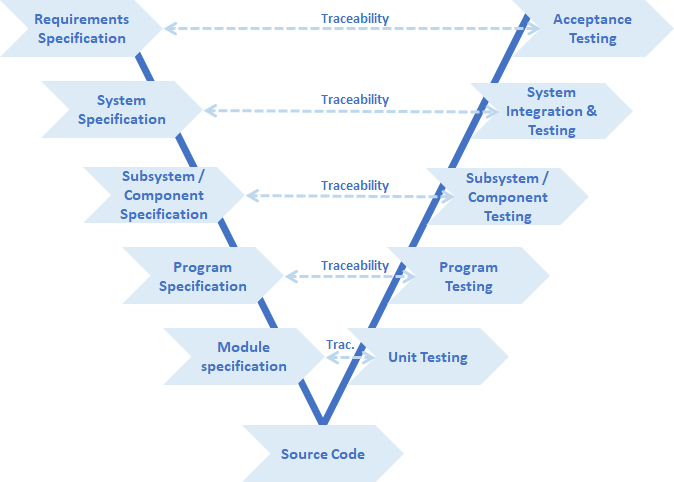
Na przykład u mnie w branży automotive przy tworzeniu oprogramowania obowiązuje norma ISO26262, definiująca proces zwany V-Model. Na obrazku wygląda to tak:
V-model w ISO26262
Zauważmy, że w tym modelu kod źródłowy (czyli właśnie kodowanie) jest na samym dole diagramu, i nie przypadkiem jest to V-model (ze szpicem w dół), a nie na przykład Λ-model (ze szpicem w górę). Kodowanie jest po prostu najmniej istotnym elementem procesu. Nawet gdyby udało się je całkowicie wyeliminować, pozostałą większość roboty i tak będzie musiał zrobić no kto? Żywy programista oczywiście.
Teraz drugi problem. Załóżmy, że AI naprawdę wygeneruje nam dobry kod, kiedy jej powiemy co ten kod ma robić. W sumie żywemu programiście też musimy powiedzieć, co ten kod ma robić. I tak typowo to nie mówimy mu tego, tylko piszemy w formie requirementów. I tych requirementów do uwzględnienia zawsze trochę jest. Na szczęście nie musimy specyfikować każdego najdrobniejszego szczegółu, bo ten programista taki całkiem głupi nie jest, i z grubsza będzie rozumiał dlaczego pewne rzeczy mają być zrobione tak, a nie inaczej (bo przecież sam jeździ samochodem), zajrzy do dokumentacji procesora (i do erraty też), będzie znał ograniczenia użytej platformy (albo o to zapyta), itp. itd. Inaczej mówiąc: będzie korzystał ze swojej i innych wiedzy o świecie.
No ale AI, jak już wiemy z poprzedniego odcinka, nie ma wiedzy o świecie. I w związku z tym specyfikacja dla niej musi być o wiele bardziej szczegółowa niż dla programisty. I w którymś momencie to przestanie mieć sens - jeżeli będziemy musieli pokazać AI paluszkiem każdy szczegół, to po jaką cholerę nam takie AI? Szybciej napiszemy to sami, bez kombinowania z tłumaczeniem (nawiasem mówiąc tak samo bywa z żywymi programistami, sytuacja że lepiej napisać samemu niż komuś tłumaczyć nie jest znowu taka rzadka). I jakoś o podobnym przypadku już pisałem przy marzeniu lat 60-tych, czyli "dowodzeniu poprawności programów": Jeżeli wyspecyfikujemy nasz program bardzo dokładnie, to w zasadzie powinno dać się z tego zrobić implementację, nawet bez AI.
Kolejny problem z requirementami jest taki, że tak normalnie to one powinny przychodzić od klienta. Tyle że klient bardzo często:
Sam nie wie, czego właściwie chce.
Przekopiował requirementy z wcześniejszego projektu, a tu niezupełnie pasują.
Nie zauważył sprzeczności w requirementach.
Nie znał ograniczeń sprzętu.
Sam nie rozumie, co właściwie napisał.
itp. itd.
Teoretycznie wszystkie takie problemy powinno dać się wyłapać zanim dojdzie do kodowania, ale to jest naprawdę tylko teoria. Zależności jest zbyt wiele, żeby tak się dało przy rozsądnym nakładzie pracy. W praktyce wcale nie tak rzadko programista przy kodowaniu musi sprawdzać, co poeta miał na myśli na którymś w wyższych etapów V-modelu, i czy na pewno jest pewny. (Dygresja: po niemiecku "poezja" to "Dichtung", tak samo jak "uszczelka", co pozwala konstruować mnóstwo bardzo suchych sucharów na takie tematy). Jakoś nie za bardzo potrafię wyobrazić sobie AI pytające autora inputu o uszczegółowienie albo uściślenie, to tak nie działa, tego ona nie potrafi.
Jest w tym wszystkim kolejny aspekt: To nie jest tak, że napiszemy kod raz a dobrze, i tak on zostanie na wieki. Zawsze wkrótce okazuje się, że coś trzeba tam jednak zrobić inaczej, wcale niekoniecznie dlatego, że nasz kod jest zły. Gdy piszemy ręcznie, poprawiamy te parę linii, aktualizujemy specyfikację tych paru testów, robimy nowe testy zmienionego kawałka i już. Tymczasem przy AI musimy kazać jej wygenerować całość od nowa, a ona jest niedeterministyczna z założenia i wygeneruje nam całkiem nowy kod, całkiem inny niż poprzedni. No i lokalność zmiany szlag trafia, trzeba od nowa robić pełne testy całości, review kodu (full, nie tylko delta), certyfikację, czy co tam jeszcze jest wymagane. Jeżeli norma wymaga pokrycia testami wszystkich branchy w kodzie, to musimy mocno pozmieniać nasze testy. I tak dalej, i tak dalej. Przecież z czymś takim nie da się pracować, to generuje więcej roboty niż było bez tego.
Oczywiście moglibyśmy generować z AI raz, a potem poprawiać w kodzie generowanym. Tyle że to nie za wiele daje - wtedy musimy analizować nie swój kod. I po kilku poprawkach i tak kod będzie w sporym stopniu nasz, nie AI. I wtedy po co nam to AI? Współczesne IDE generują nam szkielety zawartości nowych plików kodu i mogą wtykać snippety kodu w żądane miejsca, i to robić to deterministycznie - na cholerę nam bawić się w analizę intencji AI?
A już całkowicie pomijam fakt, że taki AI generator kodu absolutnie nie da się certyfikować na safety, głównie ze względu na jego indeterminizm. A w szczególności nie da się spełnić wymagań normy ISO26262 dla narzędzi programistycznych. Znaczy każdy safety-relevant kod wygenerowany przez AI musi przejść pełny review.
Teraz napiszę kontrowersyjną rzecz: Cała historia informatyki to historia walki o zastąpienie kodowania przez programistę generacją kodu. Było to tak:
Na początku komputery programowało się wpisując kody rozkazów do pamięci przy pomocy klawiatury binarnej, a później ósemkowej. Mi też się kiedyś coś podobnego zdarzyło (tyle że bez tej klawiatury), to był prawdziwy hardkor, tak się nie da pracować z kodem dłuższym niż parędziesiąt rozkazów.
Dlatego wymyślono assembler. Już nie potrzeba było hardkorowego kodera, każdy głupi mógł wpisać tekstowo op-cody rozkazów i program już działał. No ale tu też przy większych programach zaczęły się problemy z ogarnięciem kodu. (Zauważmy, że assembler jest de facto generatorem kodu - na podstawie tekstu generuje kod maszynowy)
Dlatego do assemblera dodano makra, tworząc makroassembler. Teraz każdy głupi mógł sobie radykalnie skrócić program używając makrosów. No ale tu też przy większych programach zaczęły się problemy z ogarnięciem kodu. (Zauważmy, że warstwa makro jest generatorem kodu - na podstawie tekstu makrosów generuje tekst rozkazów assemblera).
Dlatego powstał język wysokiego poziomu nazwany COBOL. Teraz każdy user mógł sobie napisać program w języku naturalnym, a komputer zrobił wszystko, czego ten user chciał. Przynajmniej jeżeli chciał zrobić jakieś operacje na bazie danych. No ale nie wszystko robi się na bazie danych. No i ta "naturalność" języka była dość relatywna. (I oczywiście taki kompilator jest generatorem kodu maszynowego).
Dlatego powstały inne języki programowania, na przykład FORTRAN, Algol 60, Algol 68, Pascal czy C. Teraz każdy głupi mógł sobie łatwo napisać program. (Zauważmy, że każdy kompilator czy interpreter jest też generatorem kodu, a do dziś wiele kompilatorów nie generuje wprost kodu maszynowego tylko kod źródłowy w assemblerze. A pierwsza faza kompilacji programu w C to preprocesor, czyli ewidentny generator kodu).
Potem zmniejszać ilość kodu miała koncepcja modularności / obiektowości (Modula2, C++, Java, ...). Jakościową zmianą w generacji kodu były na przykład Templates w C++.
Dalej pojawiły się pierwsze próby z low-code: wszystkie te języki Visual-XXX (Basic, C++, ...). Tu użytkownik miał po prostu narysować aplikację GUI, i napisać tylko troszeczkę kodu w callbackach. Resztę robił generator. To nawet jakoś działało.
Następna próba była - moim zdaniem - najbardziej obiecująca ze wszystkich: Model Driven Development. Kod miał być wygenerowany z modelu, co potencjalnie mogło zintegrować generację w cały proces tworzenia oprogramowania. To nawet działało (BTDT), ale nie było pozbawione wad i nie było dla każdego.
Po opadnięciu hype na MDD poszło to wszystko raczej w stronę konfiguracji w jakimś narzędziu i generacji kodu z templates tekstowych albo czysto programowej. Tak działa cały ten AUTOSAR i to jest mix no-code z low-code.
Do niedawna na topie było właśnie low-code i no-code, ale to są głównie scamy - przychodzi jakiś akwizytor, na pokazie w parę minut wyklikuje działającą aplikację, i managerstwo się na to łapie. A potem się okazuje, że wyklikać da się tylko to, co producent wbudował do środka, a zrobienie w tym czegoś więcej jest od cholernie trudnego do niemożliwego.
Od dłuższego już czasu IDE wrzuca szkielety kodu do nowo tworzonych plików, albo ma jakiś katalog snippetów do różnych zadań. To też jest forma generatora kodu. No i zawsze można przekopiować coś ze StackOverflow albo z jakiegoś starego projektu.
No i teraz wchodzi, cała na biało, generacja kodu przez AI. No i tak serio serio to ma być wreszcie to ultymatywne rozwiązanie, żeby już nic nie kodować? Przecież to już chyba ósma dekada tego eliminowania kodowania, że już-tylko-chwila i programiści staną się niepotrzebni. Prawie jak z tą syntezą termojądrową.
Podsumowanie: Jak na razie nie ma się czym ekscytować (no chyba że przez cały czas kodujesz maski do aplikacji bankowych, ale wtedy i bez AI lepiej się trochę przebranżowić). Jak będzie dalej? Moja prognoza w następnym odcinku.
Strasznie dawno nic nie pisałem, ale wcale nie dlatego, że nie mam o czym. Tematów jest mnóstwo, tyle że freelancerstwo zajmuje mi bardzo dużo czasu. Trudno się opędzić od klientów i projektów. Po drodze potłumaczyłem angielskojęzyczne notki WO o wojnie z jego substacka na niemiecki, pomagając sobie DeepL-em i tłumaczem Googla, i to był jeden z triggerów tej notki.
Drugim triggerem był nieustanny szum medialny o tym, jak to AI zastąpi mnóstwo zawodów, a w szczególności programistów. Akurat poczytałem trochę jak te aktualne implementacje AI są skonstruowane, połączyłem tę wiedzę z obserwacjami efektów ich działania i oto moje wnioski. Dla ustalenia uwagi: Piszę nie o AI generalnie, tylko o realnie istniejących implementacjach generujących teksty i obrazy.
Najpierw parę słów o tym, jak to (w uproszczeniu) działa. I to jest tak: To wszystko są modele językowe. Taka AI "wie" tylko tyle, że w kontekście K po słowie S1 z prawdopodobieństwem P następuje słowo S2. A "wie" to tylko z tekstów, którymi została nakarmiona. Tam nie ma żadnej wiedzy o świecie, tam są tylko słowa, słowa, słowa.
Dla zrozumienia konsekwencji mały rys historyczny. W początku wieku XX pojawił się prąd artystyczny zwany dadaizmem. Dadaiści odrzucali logikę, racjonalizm i estetykę kapitalizmu. Zamiast tego wszystkiego proponowali nonsens i nieracjonalność, a to wszystko miało być tylko "sztuką dla sztuki". Jedną z ich koncepcji było tworzenie wierszy przez losowanie słów. Tu cytat z "Manifestu Dada":
TO MAKE A DADAIST POEM
Take a newspaper. Take some scissors. Choose from this paper an article of the length you want to make your poem. Cut out the article. Next carefully cut out each of the words that makes up this article and put them all in a bag. Shake gently. Next take out each cutting one after the other. Copy conscientiously in the order in which they left the bag. The poem will resemble you. And there you are – an infinitely original author of charming sensibility, even though unappreciated by the vulgar herd.
ABY STWORZYĆ DADAISTYCZNY WIERSZ
Weź gazetę. Weź nożyczki. Wybierz z tej gazety artykuł o długości, jaką chcesz nadać swojemu wierszowi. Wytnij artykuł. Następnie ostrożnie wytnij każde ze słów, które składają się na ten artykuł i włóż je wszystkie do woreczka. Delikatnie potrząśnij. Następnie wyjmij każdy wycinek jeden po drugim. Kopiuj sumiennie w kolejności, w jakiej opuściły woreczek. Wiersz będzie przypominał ciebie. I oto jesteś - nieskończenie oryginalny autor o czarującej wrażliwości, choć niedoceniany przez wulgarne stado.
Oczywiście pełna losowość kolejności słów dawała wiersze nie nadające się nawet do czytania, więc w praktyce wycinano raczej całe linie tekstu źródłowego a nie pojedyncze słowa. Przy tym podejściu efekty bywały nawet nie najgorsze, ale sensu już programowo nie było w nich żadnego. Zwracam uwagę na proroczą linię Manifestu "The poem will resemble you" - za chwilę do niej wrócę.
Potem pojawiły się komputery, i zaczęto próbować robić podobne rzeczy na komputerze, bawiono się w to już na mainframe, pamiętam też takie programiki na Commodorka. Komputer zastąpił żmudne wycinanie nożyczkami i umożliwił ograniczenie losowości tak, żeby tekst wychodził jako-tako poprawny gramatycznie, ale sensu nadal nie było w nim żadnego.
Obecne implementacje AI idą mały krok dalej - robią ten (nadal w sporym stopniu losowy) tekst takim, jak statystycznie piszą ludzie, i to jest właśnie "The poem will resemble you". Niestety nie "an infinitely original author of charming sensibility" tylko "the average human", ale to zawsze coś. Zauważmy jednak, że nadal sens w tym wszystkim pojawia się co najwyżej jako efekt uboczny tego naśladowania człowieka - bo nie ma skąd inąd się wziąć. W moim rozumieniu sens musi brać się z wiedzy o świecie, a tu jej nie ma. Zresztą nie tylko w moim rozumieniu tak jest - na przykład Trurl tworząc Elektrybałta zaczął od wymodelowania całej historii Wszechświata, a dopiero na tej podstawie zabrał się za wierszokletstwo.
Ktoś może argumentować, że przecież taka AI ma pełen dostęp do Internetu, i może sobie wszystko wyguglać. Hmm, a powiedz, jaki procent wyników twoich zapytań googla jest sensowne i odpowiada na twoje pytanie? I w jaki sposób oddzielasz wyniki sensowne/prawdziwe (czyli zgodne ze światem rzeczywistym) od bezsensownych/nieprawdziwych? Nie przypadkiem na podstawie twojej wiedzy o świecie? Bez wiedzy o świecie możesz najwyżej powiedzieć który wynik jest podobny do twojego modelu językowego, a który nie. Nic więcej. (Dokładnie ten sam błąd popełniają ludzie twierdzący "Po co mam się uczyć, skoro mam googla?". A jakim cudem chcesz potem zrozumieć wyguglaną odpowiedź?).
Pewien czas temu można było zauważyć spory hype na automatyczne tłumaczenie. Ponieważ poćwiczyłem takie tłumaczenie na notkach WO, mogę coś na ten temat powiedzieć (przynajmniej o niemieckim jako języku docelowym). I to jest tak: Rzeczywiście oszczędza to sporo tej fizycznej roboty z tworzeniem gramatycznie poprawnych zdań w języku docelowym. Ale nadal nie można wyniku puścić bez sprawdzenia i poprawienia. Przy tym DeepL ma całkiem inny styl niż tłumacz Googla. Google gubi się w zdaniu częściej niż DeepL, ale w innych miejscach i zawsze warto porównać obie wersje. Który jest lepszy stylistycznie to kwestia gustu. Za to Google potrafi poprawnie użyć indirekte Rede, przy DeepL nigdy tego nie zaobserwowałem.
Ale oba mają ten sam problem: Brak im wiedzy o świecie. Na przykład kiedy w kontekście lat 90-tych pada nazwisko Clinton bez imienia, dla obu jest to "ona" (Hilary, a nie Bill), bo tak było w nowszych tekstach, którymi je uczono. Trzeba wyłapywać i poprawiać odniesienia do popkultury, zwłaszcza nie najnowszej (cytaty, tytuły), bo oba jej po prostu nie znają. Idiomy też są dla nich poważnym wyzwaniem. Itp., itd. Znaczy: AI usprawnia pracę tłumacza, ale nie da rady go zastąpić.
Jeszcze anegdotka: WO w swojej notce przetłumaczył (prawdopodobnie automatycznie) z rosyjskiego na angielski fanfik Girkina o puczu Prigożina w stylu "Trudno być Bogiem" Strugackich. Nie chciałem robić tłumaczenia tłumaczenia, więc znalazłem oryginał rosyjski (nie chcę linkować, jak ktoś chce zobaczyć, to proszę ręcznie: na "t.me/s/strelkovii" poszukać "Трудно быть чёртом"), przetłumaczyłem go na niemiecki obydwoma tłumaczami, i oba miały ten sam problem - były tam wspomniane "Серые Роты", czyli "Szare Roty" (albo "kompanie", takie oddziały wojska). Formy liczby mnogiej słów "Рота" i "Рот" ("pysk") są identyczne, i obu AI-tłumaczom wychodziły "die Grauen Mäuler" ("Szare Pyski" albo "Szare Mordy"). Dla informacji: W tłumaczeniu Ireny Piotrowskiej były to "Szare Oddziały".
Wróćmy do prądów artystycznych sprzed 100 lat: Dadaiści proponowali również losowość w sztukach wizualnych, np. kolaże z przypadkowych wycinków. AI też to potrafi, w praktyce dość wiernie oddając produkt generacji tekstów na obrazku. Na tyle wiernie, że wszystkie problemy aktualnych AI generujących teksty można jeszcze łatwiej zauważyć na tych obrazkach. A zwłaszcza gdy poprosimy o obrazek czegoś z tekstem, na przykład plakatu filmowego albo pudełka z setem Lego - AI umieszcza na nim grupy pikseli przypominające litery i słowa, ale nigdy nie są to sensowne i czytelne napisy. To tylko wizualnie przypomina to, co robią w tym miejscu ludzie, ale AI nie "rozumie" ich sensu.
Set LEGO według AI
Znaczy ja doceniam, że udało się zimplementować przerobienie opisu słownego w spójny wizualnie obrazek a nie dadaistyczny kolaż, ale to, co jest na tym obrazku, to nadal nie ma wielkiego sensu, właśnie ze względu na brak wiedzy o świecie generatora. Na przykład jak poprosić o obrazek o "katastrofie elektrowni w Czarnobylu", dostajemy elektrownię z kominami. Przy zwrotach typu "wycierać kurze" albo nazwach w rodzaju "Mniszek lekarski" dostajemy "jak sobie mały Kazio wyobraża znaczenie takich zwrotów".
"Wytrzyj kurze" według AI
"Mniszek lekarski" według AI
O, z tym "małym Kaziem" to jest ciekawy trop. Porównajmy sobie aktualne AI z człowiekiem. Według mnie porównanie z dzieckiem w jakimś wieku nie jest dobre, bo z jednej strony AI ma braki w wiedzy o świecie podobne do nie za dużego dziecka, ale z drugiej ma o wiele większą sprawność językową niż wielu dorosłych. Ale powiem, że poznałem w życiu trochę dorosłych ludzi na podobnym poziomie kognitywnym co ta AI. Znaczy powtarzających zasłyszane/przeczytane zdania jak z gazety na podstawie słów kluczowych, jednak bez ich weryfikacji i zrozumienia ich znaczenia. Podejrzewam, że większość moich czytelników też takich ludzi spotkała, przynajmniej w sieci. Zazwyczaj są to zwolennicy różnego rodzaju teorii spiskowych oraz partii populistycznych. Czyż na przykład płaskoziemcy nie wydają wam się skonstruowani podobnie do aktualnego AI? Znaczy że mają tylko model językowy bez modelu świata? (A może te dwa modele po prostu nie są u nich połączone?)
EDIT 2024.04.06: Przypomniałem sobie mojego znajomego Putinverstehera i ogólnie teoriospiskowca. On jest inżynierem automatykiem, urodził się w Polsce, ale od prawie 50 lat jest w Niemczech. I on pewnego razu przy dyskusji na temat znajomości języka powiedział "Ja potrafię powiedzieć więcej (po niemiecku), niż rozumiem". Wtedy mnie to rozbawiło jako oczywista bzdura, ale teraz się nad tym zastanawiam. Czyżby był to właśnie przypadek modelu językowego nie połączonego z modelem świata?
Teraz przejdźmy do konsekwencji dla rynku pracy: Widzę jeden zawód, który może z marszu zostać zastąpiony przez AI (i nie jest to zawód dziennikarza): Bezproblemowo można zastąpić wszystkich tych tekściarzy wymyślających opisy do produktów w katalogach sprzedaży wysyłkowej. To jest przecież właśnie beztreściowe blablabla, trochę podobne do tego, jak piszą ludzie. Taka generacja opisów do sprzedawanych produktów jest już dostępna dla każdego przy tworzeniu aukcji na eBayu. I powiem szczerze, że ja takich tekstów tworzyć nie umiem, AI jest tu ode mnie o wiele lepsze. Ale czy można nazwać to inteligencją?
Przy innych zawodach nie jest już tak prosto - w większości produkowane teksty muszą mieć jednak jakieś odniesienia do świata zewnętrznego. AI potrafi świetnie "lać wodę", ale kiedyś trzeba jednak dojść do konkretów. Przedstawiciele paru zawodów już zdążyli się przejechać na próbach użycia AI do ich pracy, bo generowane teksty nie wytrzymały konfrontacji z rzeczywistością (na przykład że AI zmyśliło paragrafy kodeksu karnego). Jakaś dziennikarka bardzo ładnie podsumowała swoje próby z AI: "Te teksty brzmią jakby napisał je golden retriever". To może zastąpić stażystów piszących zapchajdziury, ale nie dziennikarza piszącego o czymś konkretnym.
Podejrzewam, ze większość moich czytelników interesuje przede wszystkim pytanie, czy AI zlikwiduje ich miejsca pracy jako programistów, jednak notka zrobiła mi się na tyle długa, że ten temat wrzucę do drugiego odcinka. A może jeszcze będzie i trzeci, z moimi prognozami na przyszłość.
W pracy kończy mi się walka z programistycznymi twitami, przynajmniej w tym projekcie. Startuje powoli następny, oczywiście znowu o stopień trudniejszy (teraz będzie dużo wariantów z różną funkcjonalnością i procesor z symmetric multicore). No ale trzeba oszczędzać i pewnie mnie przy nim nie będzie, przynajmniej na początku (pewnie zawołają mnie dopiero jak się zacznie walić i palić) . Zobaczymy gdzie teraz trafię.
Ale za to w domu zabrałem się za eksperymenty z Androidem. Na początek spróbowałem działać z sensorami i też od razu natknąłem się na mnóstwo twitów:
Na początek zrootowałem swojego tableta (Acer Iconia A700). Nawet łatwo poszło.
Wgrałem mu custom recovery, całkiem fajnie działa
Wgrałem też mu custom system (CyanogenMod). Tu był problem - jest dużo programów instalujących ten system na zrootowanym urządzeniu, tyle że całkiem niedawno ten projekt przemianował się (na LineageOS) i w ogóle coś się pozmieniało i te starsze wersje zginęły z sieci. Żaden z instalatorów nie działa. Na szczęście znalazłem gdzieś w sieci odpowiedni kompilat (samemu skompilować jeszcze mi się nie udało) i wgrałem go na tableta. I to jest dobre, oryginalny Android ślimaczył się już straszliwie, a ten chodzi całkiem przyjemnie, można było wywalić cały bloatware i ma to parę funkcji więcej.
Pisałem wcześniej o problemach z emulatorem Androida, dałem sobie z nim spokój. USB debugging chodzi bardzo dobrze. Potem kupię sobie parę używanych urządzeń z różnymi rozdzielczościami.
USB debugging chodzi, tyle że nie na moim telewizorze. Philips ma politykę, że ich telewizory są nierootowalne, soft można instalować tylko z Google Play, a USB debugging mimo że można odblokować, to nie chodzi (tu jeszcze potencjalny problem połączenia USB-A z USB-A). Chociaż ostatnio trochę odpuścili, po niedawnym updacie opcja instalacji z innych źródeł się pojawiła, i co nieco narzędzi poinstalowałem. Debugging ma móc chodzić przez Ethernet, podobno komuś się z tym modelem telewizora udało, mi jeszcze nie. W ogóle to motywacja Philipsa jest "Bo jak zbrickujesz sobie telewizor za 2500 EUR to będziesz płakał" - tyle że mój telewizor był tańszy od mojej komórki i niewiele droższy od mojego tableta. Uprzedzając pytanie: Nie, nie mam komórki za 2500+.
No to zacząłem od tableta. Na początek postanowiłem zapoznać się z obsługą sensorów. Jest do tego mnóstwo przykładowego kodu w sieci.
Analiza kodu i zależności fizycznych pokazała, dlaczego niemal wszystkie (o ile nie wszystkie) programy robiące za kompas są do niczego. Przyczyny są dość skomplikowane, ale do pojęcia. Objaśnię je, bo to ciekawe:
Niemal każda komórka ma akcelerometr, którym można ustalić kierunek "w dół" (to tam, gdzie statycznie mamy przyspieszenie 1g), żyroskop do obrotów i magnetometr, pokazujący kierunek na magnetyczną północ
GPS podaje geolokalizację urządzenia, ale nie w którą stronę jest obrócone, więc GPS się do kompasowania nie nadaje.
Magnetometr podaje kierunek wprost (przez Ziemię) do bieguna magnetycznego. Znaczy to jest (jak u nas) jakieś 40º do poziomu.
Duża część programów na kompas bierze po prostu składową magnetyczną w płaszczyźnie urządzenia, relatywnie do jego osi Y. Ale jak trzymać urządzenie w ręku i pochylić je trochę do siebie, to ta płaszczyzna ustawia się paskudnie blisko prostopadłości do żądanego wektora, całą dokładność szlag gwałtowny trafia i kompas kręci się na chybił-trafił.
Sytuację może poprawić użycie kombinacji sygnałów z akcelerometru i magnetometru.
W zasadzie coś takiego jest dostępne jako wirtualny sensor pozycji urządzenia, tyle ta funkcja zrobiła się deprecated lata temu (od v2.2.x, około 2010).
Ponieważ nowe rozwiązanie wymaga jednego calla więcej i trochę zrozumienia (słowo kluczowe: quaternion), prawie nikt nie jest w stanie tego pojąć i prawie wszyscy robią to po staremu.
Nawet po nowemu, to pokazuje kierunek na północ magnetyczną, a nie na "prawdziwą" północ.
Znając geolokalizację (z GPS-u) można od systemu dostać wartość poprawki żeby pokazać prawdziwą północ, ale nie znalazłem jeszcze ani jednego przykładu żeby ktoś to zrobił. Ja też jeszcze nie załapałem w którym momencie trzeba wykonać jaką operację na quaternionach, ale dojdę do tego.
Nawet jak zrobić to dobrze, pokazywany kierunek będzie zakłócany przez zewnętrzne pola magnetyczne.
Generalnie wszystkie te programy są zrobione maksymalnie prosto - obracają obrazek igły kompasu zależnie od danych z sensora. Nie będzie to sensownie działać (nawet porządnie zrobione) jak nie trzymać komórki poziomo. Mam pomysł znacznie lepszego interfejsu użytkownika. I jeszcze parę innych pomysłów na aplikacje związane z kompasem.
Dlaczego cała ta kombinacja składowych do orientowania się na prawdziwą północ nie jest dostępna jako proste API?
Jeszcze generalna uwaga co do API Androida: W całym tym API nie są w ogóle deklarowane wyjątki jakie funkcje mogą rzucać (deklaracja throws). Jak dla mnie to jest zupełnie podstawowy brak w designie - nieprzemyślana obsługa błędów.
Notka przeleżała mi się już dobry miesiąc, głównie przez nieustanną walkę z programistycznymi twitami i związany z nią wyjazd do Meksyku. Na szczęście bieżąca kampania zbliża się do końca. Ale pojawiło się coś, czym muszę się podzielić. Był to pokazany przez arte film "Hannah Arendt". Nazwisko to oczywiście znałem, miałem też obowiązkowe skojarzenie z banalnością zła, ale jakoś tak się złożyło że "Eichmanna w Jerozolimie" dotąd nie czytałem. Film był niezły, jak na film o kimś kto głównie siedzi i pisze albo wygłasza wykłady akademickie to trzymał w niezłym napięciu. I finałowa scena polemiki na wykładzie zachęciła mnie do sięgnięcia po książkę. Zwłaszcza że w filmie wszyscy bohaterowie dzieło komplementowali, nawet jeżeli fragmenty im się bardzo nie podobały.
No i książka rozczarowuje. Znaczy relacja z procesu Eichmanna jest interesująca (chociaż przygnębiająca), dowiedziałem się z niej sporo nowych rzeczy o karierze Eichmanna, jego aresztowaniu i procesie, mechanizmach Zagłady, różnicach między antysemityzmem w różnych krajach, itd., niestety relacja jest dość chaotyczna. Narracja leci jednym ciągiem bez żadnej strukturyzacji tekstu, rozdziały wynikają chyba tylko z pierwotnego podziału tekstu na odcinki drukowane w gazecie. No ale pewnie jako inżynier mam tu zbyt wysokie wymagania. Gorzej, że z książki niewiele mogłem się dowiedzieć na temat poddtytułowej tezy o "banalności zła". Słowo "banal*" występuje w całej książce zaledwie trzy razy i to w dużych odstępach. Brak jest jakiejś syntezy, chociaż takiej jak pojawiła się w filmie. Film jest zazwyczaj gorszy od książki, więc sądziłem że finałowa scena wykładu to tylko okrojony wybór fragmentów z tekstu, tymczasem było to właśnie to, czego w tekście brakowało. W dodatku zasadniczą treścią sceny były wyjątki z polemiki z krytycznym listem, nie należącej do pierwotnego tekstu, a tylko dodanej w późniejszych wydaniach jako postscriptum.
Jako przyczynek do "banalności zła" film jest znacznie lepszy niż książka. Na przykład książka tylko wspomina o tym (dwa razy), że Eichmanna na procesie pytano czy zabiłby swojego ojca gdyby Führer kazał, film zawiera oryginalne nagranie filmowe z procesu i pokazuje cały dialog, bardzo mocny zresztą. A akurat ten dialog bardzo dobrze ilustruje tezę autorki, naprawdę nie rozumiem dlaczego w książce nie został przytoczony. W praktyce to podtytuł "Rzecz o banalności zła" jest bardziej efektowną reklamą, niż oddaje treść książki. To znaczy książka jest też o tym, ale uzasadnienie tezy jest tylko "do samodzielnego montażu" - trzeba samemu znaleźć w książce odpowiednie argumenty i zsyntetyzować własnoręcznie. Niecierpliwym polecam jednak film. A pozostałym i książkę, i film, raczej zaczynając od filmu.
Teraz może coś o samej tezie. Autorka przed procesem Eichmanna była przekonana że zło zawsze jest "radykalne", a proces przekonał ją, że może być "banalne". Banalność miała postać niezbyt rozgarniętego i zapatrzonego w siebie nieudacznika Eichmanna, człowieka zupełnie przeciętnego i nudnego, który zza biurka zorganizował logistycznie zabicie milionów ludzi, nie potrafiąc przy tym odróżniać dobra od zła. Ja jakoś nie jestem przekonany, żeby zjawisko było takie nowe - przecież już w Rzymie cezarów jacyś przeciętni i nudni urzędnicy zza ówczesnych odpowiedników biurek organizowali zaopatrzenie legionów idących wyrzynać zbuntowaną ludność tu czy tam. I nie trzeba zaraz nikogo wymordowywać, normalne korpo też opiera się na takich ludziach, którzy zrobią wszystko co im się każe, bez zastanawiania się nad etyką. Patrz aktualny skandal dieslowski Volkswagena - przecież tam z całą pewnością nikt nie zrobił nic z uświadomionej złośliwości, czy innych niskich pobudek. Wszyscy robili to, co uznawali za dobre, każdy w swoim kawałku, najwyżej leciutko naciągając zasady, bo zawsze znalazły się jakieś usprawiedliwiające okoliczności. Przecież ja też robię w takim korpo i bywam na przykład na zebraniach z udziałem szefa całej fabryki. I to jest taki sam chłopek-roztropek jak ten uwieczniony na materiałach filmowych z procesu Eichmann. Praktycznie każdy rodzaj działalności ludzkiej wymaga współdziałania w większym zespole, skutki decyzji podejmowanych na wielu stanowiskach pojawiają się często o wiele później i zupełnie gdzie indziej. Odpowiedzialność się rozmywa, łatwo jest powiedzieć sobie jakieś "ja tylko..." I tak będzie zawsze.
Jedno tylko mnie niepokoi. Banalny i przeciętny Eichmann był idealnym zwolennikiem dowolnej dyktatury. On nigdy nikogo nie zabił, ale zabiłby swojego ojca gdyby Führer powiedział że to zdrajca i trzeba go zabić. Ja rozumiem że tacy ludzie istnieją, jest ich w populacji całkiem spory procent i trzeba z tym żyć. Tylko ostatnimi czasy znowu udaje się różnym takim ich skutecznie zmobilizować. Świat nie idzie w dobrym kierunku. Tylko co na to poradzić?
Dziś kolejne doniesienia z frontu walki z programistycznymi twitami, bo na nic innego chwilowo nie mam czasu.
Projekt w którym dotąd robiłem ma od dłuższego czasu dwa projekty pochodne dla dwóch innych modeli samochodów. Jeden z tych dwóch ma dwa warianty - z HUDem i bez. No ale to wszystko jest na tej samej bazie sprzętowej i ma robić z grubsza to samo, różnice są głównie w wyświetlaczu, rozłożeniu LEDów i zegarkach pokazujących niekoniecznie to samo. Tylko wziąć ten wcześniejszy projekt i trochę dopasować. No i prawdziwy twit manager of the year potrafi spieprzyć nawet coś takiego - każda z tych wersji jest wyraźnie inna, te same moduły są w różnych wersjach, albo są wręcz zupełnie inne, nawet mnóstwo nazw tych samych obiektów się nie zgadza. Nikt tego po prostu nie pilnuje. Największy problem jest z jednym z zasadniczych modułów, już w tym pierwszym projekcie on jako-tako działa tylko dlatego, że kiedyś połowę jego zrobiłem na nowo rysując statechart w Rhapsody i generując kod. Teraz zreimplementowałem go całego również w Rhapsody, narysowałem czyste i klarowne statecharty z dobrze zdefiniowanymi interfejsami, w dwa dni było zrobione, a teraz od półtora tygodnia próbuję to zintegrować z wszystkimi trzema systemami. No i wyłazi na każdym kroku to, co im powtarzam od lat: Tak się nie da pisać programów tej wielkości. Ten system jest zrobiony w AUTOSARze - to taka koncepcja modułowości do C, całkiem nie najgorsza (chociaż w pewnych aspektach nie domyślana do końca). Działa to mniej więcej tak, że każdemu modułowi definiujemy w XML porty z dobrze wyspecyfikowanymi interfejsami, a potem te porty łączymy, też w XML, są do tego narzędzia. Całość klei generowany kawałek kodu. Konsekwentnie użyte dałoby to niezły, modularny system, mimo że w C. Tyle że te twity cały czas idą po linii najmniejszego oporu i przestawiają na AUTOSAR tylko to, co absolutnie niezbędne, a pozostałe połączenia międzymodułowe są nadal robione jak ćwierć wieku temu przez #define funkcja1 funkcja2, potem w innym miejscu jest #define funkcja2 funkcja3 i tak dalej. W rezultacie nie ma żadnej modularności, a system przypomina węzeł gordyjski.
Przy okazji zauważyłem, że te nowe projekty kompilują się dobrze ponad dwa razy dłużej niż ten pierwotny, mimo że są mniejsze. Oczywiście nikt z twitów się nie skarży, ale przy czasie rekompilacji powyżej pół godziny rozsądna praca nie jest możliwa, i jest to jedna z przyczyn dlaczego te projekty są w stanie katastrofalnym. Postawiłem hipotezę roboczą, że gdzieś kluczowy header file inkluduje o wiele za dużo. Sprawdziłem i się okazało, że losowo wybrany plik źródłowy inkluduje pośrednio 55.000 headerów. Tak, dobrze widzicie: słownie pięćdziesiąt pięć tysięcy. Krótka analiza pokazała, że to idzie tak: AUTOSAR ma taki specjalny mechanizm definiowania, do której sekcji linkera dany obiekt ma iść - definiuje się powiązany z tą sekcją symbol preprocesora i includuje plik "MemMap.h" (przed obiektem i po obiekcie, zarówno przy definicji jak i deklaracji). Ten plik includuje wszystkie pliki z konkretnymi definicjami, a jest ich z grubsza tyle, ile modułów. To już robi całą masę includów. Ale teraz każdy z tych plików includuje zawsze ten sam plik z definicjami kompilatora, a przecież wystarczyłoby raz. Wywaliłem te niepotrzebne includy i ilość pośrednich includów w moim losowym pliku źródłowym spadła zaraz o 20.000 a czas rekompilacji spadł o jakieś 10%. Zawsze coś, ale w tym pierwszym projekcie jest dokładnie ten sam problem i to nie jest przyczyna różnicy czasów kompilacji. Na moje oko przyczyną jest to, że większość modułów includuje losowo i bez sensu, w pierwszym projekcie dużo tego wyczyściłem albo kazałem ludziom wyczyścić, a w tych nowych nikt się tym nie zajął, ani nawet nie przeniósł do nich poprawek. Niby drobiazg, ale 15 niepotrzebnych minut na każdą kompilację, przy sporym zespole przekłada się na stratę liczoną w osobodniach na tydzień!
W tym pierwotnym projekcie już dawno temu zauważyłem, że kompilacja idzie bez sensu: kompilowało się równolegle na pięciu corach, tyle że największy plik (wygenerowany przez AUTOSAR), kompilujący się przez 6 minut jest w grupie o nazwie alfabetycznie prawie na samym końcu. W związku z tym na końcu pozostałe cory nie mają nic do roboty, a jeden jeszcze przez 5 minut mieli ten jeden plik. Przesunąłem więc tą grupę na początek i voila - kompilacja skróciła się o prawie 5 minut czyli 30%.
W ogóle problematyka czasu i wygody kompilacji i ich wpływu na produktywność, a nawet sukces projektu jest mocno niedoceniana. Znany jest mi wypadek projektu który padł, bo każda generacja kodu z modelu trwała ponad 30 minut. Poprzednią robotę rzuciłem między innymi dlatego, że klient dla którego robiliśmy wymyślił sobie świetny tooling: Program (w Javie) składał się z sześciu części, i żeby je skompilować trzeba było każdą część kliknąć z osobna, i to nie wszystkie naraz, ale po kolei. Każda część kompilowała się 3-4 minuty, czyli akurat tyle żeby tymczasem się przełączyć i coś porobić. Tyle że jak się potem przełączało do Eclipsa to było zawsze "O k..., znowu nie pamiętam który ostatnio klikałem!". Focusu już nie było, z konsoli też nie dało się łatwo wywnioskować. Efekt był taki, że klikało się parę razy w to samo, albo coś się pomijało i trzeba było od wszystko od nowa. Rozwiązania typu notować na karteczce, albo cały czas się gapić w tego Eclipsa były tak upierdliwe, że aż poszukałem książki od tego badziewia, ale po paru godzinach prób zrobienia żeby wszystko startowało się automatycznie z Anta dałem spokój. Nie dało się i już. Mój szef, też bardzo dobry w te klocki, nie chciał w to uwierzyć, sam się za to zabrał ale wkrótce też się poddał. Dla zainteresowanych podaję słowo kluczowe, po usłyszeniu którego trzeba szybko uciekać: Buckminster.
Na zakończenie coś dla zmniejszenia hermetyczności notki. Przykłady twitowego i nietwitowego designu UI w elektronice konsumpcyjnej. Najpierw twitowy:
Budzik z twitowym UI
To jest typowy budzik za kilka euro, różne warianty i odmiany można kupić w każdym sklepie. Każdy ma trochę inne ustawianie czasu budzenia, praktycznie zawsze nieintuicyjne. Podejrzewam, że projektanci tego sprzętu w ogóle go nie używają, albo mają jakieś zaburzenia ze spektrum autystycznego i obudzeni w środku nocy, po ciemku, bez problemu potrafią przypomnieć sobie sekwencję klawiszy konieczną żeby alarm na stałe wyłączyć.
Ten konkretny model jest jeszcze bardziej twitowy, bo piszczy przy każdym przyciśnięciu przycisku. Autor tego rozwiązania jest z całą pewnością samotny, albo mieszka u rodziców i ma swoją, osobną sypialnię, nie dzieloną z nikim. Ale przy tak daleko posuniętym autyzmie to nic dziwnego.
A można inaczej. UI tego budzika jest zrobione genialnie:
Budzik z nietwitowym UI
Włączenie i wyłączenie alarmu robi się przy pomocy suwaków z boków. Suwak w górę - alarm włączony, suwak w dół - alarm wyłączony. Czas alarmu ustawia się po po przyciśnięciu jednego z tych większych przycisków po lewej i po prawej. Z wyświetlacza znika wtedy wszystko poza ustawianym czasem i naprawdę nie sposób tego nie umieć, nawet bez instrukcji.
Budzik z nietwitowym UI - ustawianie czasu
Suwaki podnoszą oczywiście koszt całości o kilka centów - bo program to żadna różnica, te kilkanaście linii kodu przeliczone na wielkość produkcji to koszt przyzerowy. Za to za taki budzik kasują 25 euro (sugerowana cena producenta), w sieci daje się znaleźć oferty od kilkunastu. W bonusie ma jeszcze różne cuda z podświetleniem wyświetlacza. Można? Można!
Poprzednia notka spotkała się z żywym odzewem czytelników, więc ponieważ ostatnio temat bardzo mnie zajmuje - zarówno w pracy jak i prywatnie - to może następna.
W pracy ostatnio miałem satysfakcję z gatunku Schadenfreude - od dobrych dwóch lat marudzę przy każdej okazji szefowi działu że tak jak robią to nic z tego nie będzie i trzeba coś zmienić (lista propozycji w załączeniu). Oczywiście, jak to w korpo, nic się nie zmienia. Projekt w którym jestem udało mi się doprowadzić do jako-tako szczęśliwego końca w zasadzie tylko w taki sposób, że co poważniejsze problemy popoprawiałem na własną rękę albo powymuszałem różne rzeczy tworząc fakty dokonane. Ale równolegle idzie projekt pochodny, do innego wariantu, w zasadzie tylko przejąć ten "mój" i trochę pozmieniać. Tego nowego projektu dotąd nawet nie dotknąłem i jest on w stanie tragicznym. No i w czwartek szefu był u klienta na zebraniu kryzysowym, pojawił się tam szef działu testowania (zresztą o polskim nazwisku), stwierdził że jakość tego softu jest katastrofalna (co i ja ciągle szefowi mówię) i zaczął zadawać pytania w stylu "a czy macie development patterny?", "a czy macie continous integration?", "a czy macie automatyczne testy?" - i wszystkie te pytania pokrywały się dokładnie z tym, o czym marudzę. No i już w piątek było "Powiedz nam, co mamy robić żeby ten projekt się nie zawalił?".
Jak źle jest? SOP jest na marzec, to jest do tańszego modelu więc od samego początku ilości będą rzędu 5000 tygodniowo, a na dzień dzisiejszy kompilator daje aż 25.000 warningów. Szybko przejrzałem listę i zauważyłem, że większość z nich musi być z bardzo niewielu miejsc - pół godziny szukania, znalazłem że w dwóch miejscach ktoś zainkludował headery wewnątrz funkcji. Po usunięciu ich, ilość warningów spadła do poniżej 10.000. Rzecz graniczy z sabotażem. Funkcjonalnie to nawet nie przejęli sporej części rzeczy, które od dawna działają u nas. Jedną dość kluczowy moduł infrastrukturalny który opracowałem, zamiast go po prostu przejąć zrobili "lepiej". Poświęcili na to masę czasu, zawracali mi dupę mnóstwo razy, ale oczywiście nie zintegrowali najpierw mojej wersji, tylko od razu zabrali się za poprawianie, czym opóźnili o miesiące włączenie mechanizmów ochrony pamięci - które przecież pozwalają znaleźć sporo błędów. Na koniec jeszcze nie wszystko działa, a nie mają z tego wszystkiego żadnych zalet poza tą abstrakcyjną "lepszością". Za to będzie teraz źle, bo rozwiązania tego samego w obu projektach są różne (a na przykład cały generator kodu jest wspólny, oni poprawiają moje zmiany za każdym razem). Przy pierwszym problemie każę im to wywalić do kosza i wrócić do mojego. Tragedia po prostu, znowu trzeba będzie ratować im dupy, za każdym razem z coraz głębszego szamba.
No dobrze, ale bywa jeszcze gorzej. Wróćmy do naszych ulubionych Twit Programmers z consumer electronics.
Mam w domu zegar ścienny z DCF, produkcji znanej firmy Citizen. Trochę lat już ma. Taki zegar synchronizuje się z nadajnikiem DCF-77 (tu niedaleko, koło Aschaffenburga) w południe i o północy, jeżeli wychodzi mu że się spóźnia to nie ma sprawy - wskazówki pojadą trochę do przodu. Gorzej jest, jak się spieszy - taki zegar do tyłu się nie pokręci. Ja bym zrobił tak, że zegar powinien trochę poczekać aż upływ czasu dogoni czas wskazywany, a potem niech chodzi dalej, w końcu o ile może się pospieszyć przez 12 godzin. Tymczasem tutaj jakiś twit programmer wymyślił, że zegar pokręci się niecałe 24 godziny do przodu. Ponieważ to stara konstrukcja i wszystkie wskazówki są posprzęgane na stałe, to sekundnik musi się w tym celu obrócić 12*60=720 razy dookoła, a trwa to prawie 20 minut. Oczywiście spać się w tym pokoju nie da, jak zegar o północy przez 20 minut warczy. A teraz najlepsze: Zegar przy czasie letnim ZAWSZE stwierdza, że się spieszy - ten twit nie uwzględnił przy porównaniu flagi DST.
Teraz honourable mention dla elektroników którzy projektowali mojego notebooka marki Acer. To jest 18'' desktop replacement i ma dwie karty graficzne. Jedna (Intel) jest wolna, ale bierze mało prądu, druga (ATI Radeon HD4670) odwrotnie. Tyle że jakiś twit wymyślił, że ta szybka będzie niestandardowa i będzie wymagała specjalnego drivera. Notebook był zaprojektowany do Windowsów Vista, ja kupiłem go z Windows 7 i na początku ta szybka karta jeszcze działała. Potem, po jakiejś aktualizacji systemu przestała, w Windows 10 też nie działa. Aktualizacji drivera już nie ma i nie będzie, szlag by ich trafił. Pod Linuxem też nie chodzi, bo tam specjalnego drivera też nie ma.
Problem jest taki, że załamany twitami piszącymi soft na Androida wymyśliłem, że sam sobie napiszę rzeczy które potrzebuję. Zainstalowałem Eclipse z developmentem do Androida, on ma emulację urządzenia z Androidem. Tyle że na moim notebooku ta emulacja startuje się 11 minut. Popatrzyłem co się da zrobić i radykalne przyspieszenie dałoby włączenie hardwarowej wirtualizacji, ale do tego potrzebne jest Intel Virtualisation Technology w procesorze, a w moim tego nie ma. Następna możliwość to włączenie opcji użycia hardware karty graficznej, a tutaj ta szybka nie działa, a do wolnej nie ma już aktualnych driverów. No to może Linux? Partycję z Linuxem miałem, zainstalowałem tam takiego samego Eclipsa, Linux ma driver do tej karty od Intela i emulacja startuje w minut pięć. No to może nie ideał, ale zawsze znacznie lepiej. Na razie zorganizuję sobie to wszystko, a jak dojdę do poważnej roboty to kupię nowego notebooka.
Tak więc przeszedłem na Linuxa na notebooku. Poinstalowałem na moim serwerze Linuxowym trochę serwerowych narzędzi żeby robić development porządnie, i tu też zaraz wykryłem paru twitów. Na przykład u Epsona. Linuxowy driver drukarki od Epsona występuje w dwóch wersjach: Jedna drukuje wszystkie kolory poprzesuwane o parę milimetrów, druga trafia z kolorami we właściwe miejsca, ale wcale nie drukuje koloru żółtego. Wybór należy do Ciebie.
Następny twit jest od projektów do Eclipse. Zainstalowałem na serwerze CDO Repository Server żeby trzymać moje modele w czymś porządnym. A tu jakiś twit nie upilnował, żeby nazwy tabel w bazie danych były pisane zawsze tak samo. Na Windowsach nie ma problemu - tabele lądują w plikach a Windowsom jest scheissegal czy piszemy nazwy plików dużymi czy małymi literami. Ale Linuxowi nie jest to obojętne i od razu wychodzi błąd że nie można znaleźć tabel. Jako workaround podają żeby włączyć w MySQL-u opcję konwertującą nazwy tabel do małych liter, ale ta opcja jest globalna dla całej instancji serwera bazodanowego i wtedy zaczynają mi się wywalać wcześniej utworzone bazy, w których nazwy tabel zawierają duże litery. Wygląda na to, że na początek będę musiał poprawić na własną rękę CDO Server Project (na szczęście jest w źródłach).
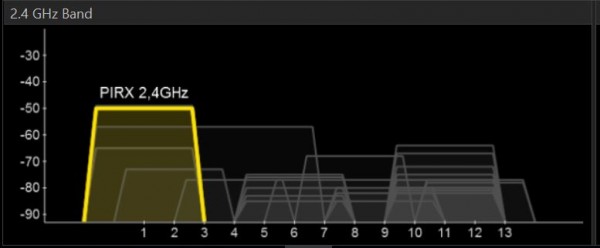
I tak dalej, i tak dalej. Teraz na pociechę: Nie każdy problem z softem/hardwarem jest wywołany przez twitów. Typowy przykład to "na początku mój WiFi stick/WiFi router/urządzenie z WiFi chodziło dobrze, a teraz coraz wolniej, na pewno to przez jakiegoś twita od driverów". Otóż nie. Jak kupowałeś tego sticka, WiFi miało tylko trzech sąsiadów i to nie w Twojej klatce. Teraz WiFi mają wszyscy, a kanały mają poustawiane całkiem randomowo. Tak wygląda to u mnie w paśmie 2,4 GHz.
WiFi w paśmie 2,4GHz
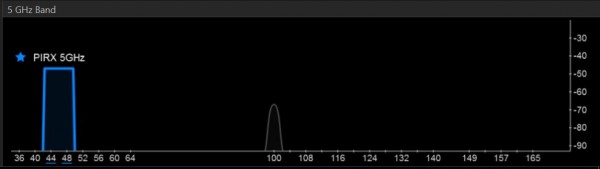
WiFi jest o tyle źle zrobione, że komunikacja na kanale n zakłóca komunikację na kanałach od n-2 do n+2. Jakby poprzydzielać kanały jakoś centralnie to jeszcze może dałoby się to jakoś opanować, ale tak w realnych warunkach sieci jest tyle i poustawiane są na tyle źle że całość się ślimaczy. U mnie było jeszcze gorzej, bo pojawiał się jakiś nieprawdopodobnie mocny sygnał (chyba z biurowca naprzeciwko) zagłuszający wszystko dookoła. Jest na to tylko jeden sposób - przejść na pasmo 5GHz. Tak wygląda u mnie pasmo 5GHz: