Dziś będzie o multitaskingu.
Wiecie, ja na codzień robię te systemy AUTOSARowe. Tam chodzi podręcznikowy multitasking plus przerwania, dokładnie jak napisane w książkach o systemach operacyjnych - z priorytetami tasków, wywłaszczaniem (lub nie), eventami do tasków, różnymi mechanizmami synchronizacji, schedule table, hookami itp. itd. I to wszystko jest mniej lub bardziej ręcznie konfigurowane, a system operacyjny jest w źródłach i można sprawdzić, zdebuggować, a nawet zmodyfikować dowolny szczegół (przy modyfikacji pamiętając, że dostawca OSa wykręci się wtedy od jakiejkolwiek odpowiedzialności za cokolwiek, nawet w zupełnie innym miejscu). Zajmuję się też robieniem ochrony pamięci przy pomocy MPU, znaczy to ja określam co i kiedy w rejestry tego MPU ma się wpisywać (bo standardowa obsługa w AUTOSARze jest marnie wymyślona, żeby działało jak trzeba trzeba to zrobić po swojemu, głęboko ingerując w system). I zajmuję się problematyką różnych call contextów, żeby się nie mieszało. I robię też obsługę wyjątków oraz integrację coretestów. Większość tego (poza MPU) nie należy do zakresu moich obowiązków, ale co pewien czas jestem wołany do pomocy w gaszeniu, jak coś się pali. Czyli mam o tym pojęcie, aż do najniższego poziomu, nawet pojedynczych instrukcji procesora (a nawet całkiem różnych procesorów, bo co projekt to inny core, inny zestaw instrukcji, inne MPU, inna koncepcja wyjątków, ...).
No i teraz zajmuję się tym moim programem pod Windowsy. Enterprise Architect jest bardzo stary, w momencie gdy powstawał, procesory pecetowe miały zazwyczaj tylko jednego cora, więc nic dziwnego że on cały chodzi w jednym threadzie. Ja dokładam do niego plugina który robi sporo niezależnych rzeczy, więc można by spróbować to czy tamto puścić w nim w innych threadach, żeby szybciej było. Tu i ówdzie mi się udało, ale ciągle mam poważny problem: Ja za cholerę nie rozumiem, jak działa threading w Windowsach/.NET! Wielokrotnie próbowałem o tym poczytać, ale nigdzie nie ma porządnego opisu podstaw z jakimiś paroma rysunkami, znajduję tylko całe strony jakiegoś blablabla TL;DR który "wyjaśnia" jak technicznie z tym działać, ale nie odpowiada na moje całkiem podstawowe i zasadnicze pytania.
Bo sytuacja jest taka: Chodzi sobie ten EA, i przez COM ładuje mojego plugina. I EA wywołuje, też przez COM, jakieś funkcje w moim pluginie, one coś robią. Tu jest jasne, to jest ciągle ten sam thread. Ale dalej, zmiany które zrobiłem w danych elementów dialogowych są jakimś cudem wyrysowywane na ekranie, ma to być podobno GUI thread. No i jaka jest relacja tego GUI threada do tego głównego threada? Z obserwacji wynika, że one chodzą na tym samym corze, ale jak są schedulowane?
Niedawna walka: Mam ja taki sobie splash screen pokazywany przy starcie EA, to jest zwyczajne okienko otwierane i zamykane podczas startu EA, wszystko w obrębie funkcji obsługującej jeden event EA. Na początek włożyłem mu w tło obrazek, i wszystko działało zgodnie z oczekiwaniami. Potem stwierdziłem, że na tym splashu wypiszę numer wersji mojego plugina. Postawiłem na nim labela, wpisałem do niego z kodu numer wersji, puściłem - i zamiast ładnego napisu dostałem biały prostokąt. Po kilku próbach poustawiania różnych propertiesów dałem spokój, i zrobiłem to samo z edit boxem. Tu było trochę lepiej - mój tekst się pojawił, ale zaselektowany. Ale tak nie może przecież być, żebym miał mocno niebieskie tło do tych kilku liter. No to podstawiłem w jakimś evencie SelectionLength=0 - nie zadziałało. To w innym evencie - też nie. Jeszcze paru - nadal nic. Sprawdziłem - żaden z tych eventów nie był wywoływany. Tu mi zaczęło świtać: Jestem w obsłudze eventu, więc nie jest wołany GUI Thread i controle nie są rysowane. No i co w tym momencie zrobić? Na koniec poradziłem sobie wywalając controle i rysując mój numer wersji po prostu na załadowanym do pamięci obrazku, jeszcze przed otwarciem okna. Ale moje pytania nadal pozostały bez odpowiedzi.
A potem dochodzi następny stopień trudności: Puszczam sobie explicite nowy thread, ale chciałbym pokazywać jak mu idzie w pasku postępu w GUI. No i jakie są relacje między tymi wszystkimi threadami? Pasek postępu zatrzymuje się co i raz, dlaczego dokładnie i jak to poprawić? Nikt nic na ten temat nie wie.
Jak już przy tym jesteśmy, to jeszcze opowiem anegdotę o guru Beelekensie - drugi raz, kiedy zajrzałem do jego kodu, był właśnie przy threadach. No i zobaczyłem tam jego komentarze, że miał problemy, ale zrobił jakieś workaroundy i już gubi eventy najwyżej z pięć razy na dzień pracy. Zainteresowało mnie to, i skopiowałem jego rozwiązanie do siebie. Gubiło tak gdzieś ze trzy eventy na dziesięć, śmiech na sali. Gdzie ma problem, zauważyłem już przy kopiowaniu - błąd było widać na pierwszy rzut oka. Poprawiłem, usunąłem workaround i poszło bez zarzutu. Uśmiejecie się, jak napiszę, co to było: On miał kolejkę na eventy pomiędzy threadami, i użył do tego klasy Queue, bez żadnej ochrony. Poprawka polegała na użyciu specjalnie do takiego celu przeznaczonej klasy ConcurrentQueue. I tyle. Nie trzeba wiele, żeby być guru w niszy.
(Wyjaśnienie dla mniej kumatych w tej działce: Tu mamy kolejkę eventów między threadami. Z jednej strony dodaje się event w jednym threadzie, z drugiej wyjmuje się go w innym. Teraz problem polega na tym, że jeżeli w trakcie dodawania obiektu thready zostaną przełączone i drugi thread wyjmie element zanim wszystkie zmienne zostaną zaktualizowane po stronie pierwszego, to kolejka może nam się pomieszać i coś zginie. Trzeba więc zapewnić, żeby operacje dodawania i wyjmowania były nieprzerywalne (atomowe) - i to właśnie zapewnia klasa ConcurrentQueue) .
W sumie brak specyfikacji jak działają taski/thready to jest problem nie tylko Windowsów. Na przykład dawno temu kupiłem synowi Lego Mindstorms, te wczesne, z żółtym brickiem. Programowało się to wizualnie przy użyciu programu o nazwie RCX Code, w sumie koncepcja była zbliżona do typowych flowchartów albo UMLowych activity diagramów.
Nie wkleję własnego screenshota z programu, bo ten system też był bardzo twitowy - chodził tylko na Windows 98 i tylko w rozdzielczości bodajże 800x600. Ta rozdzielczość była hardcoded i dla visual programming była o wiele zbyt mała. Dziś dałoby się to ewentualnie puścić na maszynie wirtualnej z Win98, ale przy tych 800x600 to i tak byłaby jedna wielka męka, więc nie warto. Jeżeli ktoś chciałby się w tego RCXa bawić, to opracowano do tego support dla różnych "normalnych" języków programowania, nie trzeba używać akurat tego RCX Code.
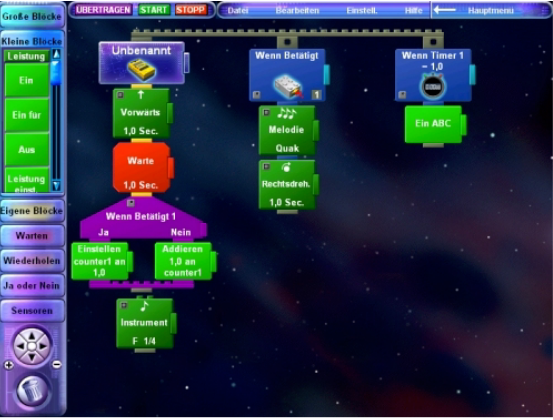
RCX Code, Źródło
Zrobiony graficznie kod reagował na zdarzenia zewnętrzne, oprócz głównego threadu można było też wyklikać kod dla obsługi eventów od różnych wejść albo timera (jak widać na obrazku wyżej). I tu też żeby zrobić coś porządnie wypadałoby wiedzieć, jak to wszystko dokładnie działa - interrupt? polling? jak schedulowany?, czyli dokładnie te same pytania co w Windowsach. W dokumentacji LEGO nic na ten temat nie było.